Part 1 — The Healthcare Data Problem
- Alex Frketic
- May 21
- 3 min read


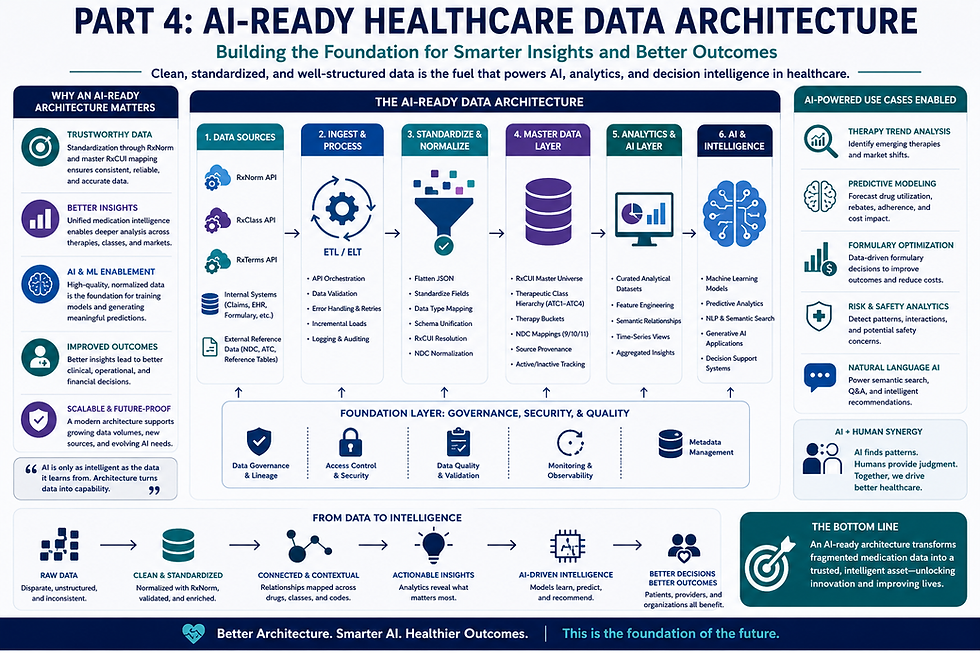
Healthcare organizations generate enormous volumes of medication-related data every single day. From pharmacy claims and formulary systems to electronic health records and rebate reporting, medication data exists across dozens of disconnected systems that often communicate using different standards, formats, and identifiers. While this information contains tremendous analytical value, the challenge lies in turning that fragmented information into something actionable, scalable, and understandable. That challenge became the foundation of my RxNorm integration project.
At the center of this problem is healthcare interoperability. In simple terms, interoperability refers to the ability for systems, applications, and databases to communicate with one another in a meaningful way. The healthcare industry has historically struggled with this issue because organizations frequently store clinical data differently depending on the platform being used. A medication may appear under one naming convention in one database, an entirely different identifier in another system, and a separate National Drug Code (NDC) elsewhere. For analysts and engineers, this creates a major obstacle when attempting to perform large-scale analytics or build AI-ready datasets.
This is where RxNorm becomes critically important. RxNorm serves as a standardized clinical drug vocabulary developed by the National Library of Medicine. Its purpose is to normalize medication names and connect them to standard identifiers known as RxCUIs (RxNorm Concept Unique Identifiers). By using RxCUIs as a universal translation layer, healthcare organizations can unify medication information across multiple systems and data sources. In many ways, RxNorm acts as the “common language” that allows disparate healthcare systems to understand one another.
The significance of this problem extends far beyond simple reporting. Big data in healthcare depends on consistency, normalization, and scalability. Without a standardized framework for medication terminology, organizations struggle to perform accurate forecasting, therapeutic analysis, pharmacy trend modeling, specialty drug analysis, and AI-driven decision support. Data scientists and analysts cannot reliably build predictive models if the underlying medication data is fragmented across incompatible structures.
One of the most eye-opening realizations during this project was understanding how complex healthcare data truly becomes at enterprise scale. Medication datasets are not simply “large spreadsheets.” They represent highly interconnected ecosystems of clinical concepts, therapeutic relationships, drug classifications, and regulatory standards. A single medication may connect to multiple therapeutic classes, ingredient structures, NDC representations, and clinical concepts simultaneously. Managing those relationships requires both strong engineering methodology and careful architectural planning.
For individuals interested in expanding their Python programming experience, projects involving healthcare APIs provide an incredible learning opportunity. Before beginning this project, my experience with APIs was limited compared to where it is today. Building this integration framework forced me to learn how APIs behave in real-world environments rather than only understanding them conceptually. I learned how to authenticate requests, process JSON responses, flatten nested structures, handle rate limits, manage retries, and engineer scalable workflows capable of processing thousands of requests.
More importantly, this experience demonstrated how programming becomes significantly more meaningful when it solves a real business problem. It is one thing to write a Python script that pulls a small amount of sample data; it is another challenge entirely to design an automated integration framework capable of normalizing healthcare terminology across multiple federal healthcare APIs. The technical learning experience became far more impactful because every engineering decision connected directly to a larger analytical goal.
Another major lesson from this process involved understanding that healthcare analytics is not solely about coding. Successful analytics projects require a combination of technical engineering, business understanding, data governance, and operational strategy. Throughout this project, every API endpoint, data merge, and normalization decision needed to align with a broader objective: creating scalable healthcare intelligence that could support future analytics, automation, and AI initiatives.
Ultimately, the healthcare data problem is not simply about volume. It is about structure, consistency, and usability. Organizations do not struggle because they lack data; they struggle because transforming raw data into reliable intelligence is extraordinarily difficult. Projects like RxNorm integration highlight how important data engineering has become within modern healthcare ecosystems. As healthcare organizations continue investing in analytics and artificial intelligence, the ability to standardize and normalize clinical data will become increasingly essential.
This project became much more than an API exercise. It evolved into a deeper understanding of how data architecture, interoperability, and engineering strategy shape the future of healthcare analytics. It also reinforced one of the central philosophies that continues to guide my work: technology and AI should help healthcare professionals make better decisions, not replace them. The goal is to elevate healthcare through better information, stronger infrastructure, and more intelligent systems.


Comments